Ideas on transitioning from monolith to manifold of models
my thoughts on a visual-question answering pipeline inspired by the Society of Minds
From monolith to manifold
The common trend in deep learning is to propose a single model which can achieve SoTA performance on some well-established benchmark. However, models proposed which achieve high performance in different benchmarks carry their advantages and limitations. For example, a VQA model with a vision encoder pretrained on rare skin lesions may answer queries more accurately from patients with these edge cases, but perform badly on common lesions. Another VQA model (which could be an ablation of the former) may perform better at spotting normal skin lesions and perform badly on rare diseases. A question which arises is how can we combine their strengths and address each other’s limitations, akin to members of a team compensating for each other’s level of expertise. One approach is to combine multiple VQA models to leverage their interoperability so that they can discuss with each other as proposed in https://nips.cc/virtual/2023/76544, transitioning from a monolith model to a manifold of models. The proposed training and inference regime is very similar to the work of García and Lithgow-Serrano, (2024) found in https://aclanthology.org/2024.clinicalnlp-1.45.pdf, where the difference lies in that we propose multiple VQA model responses, instead of responses from a single VQA model, to be summarized by a powerful LLM.
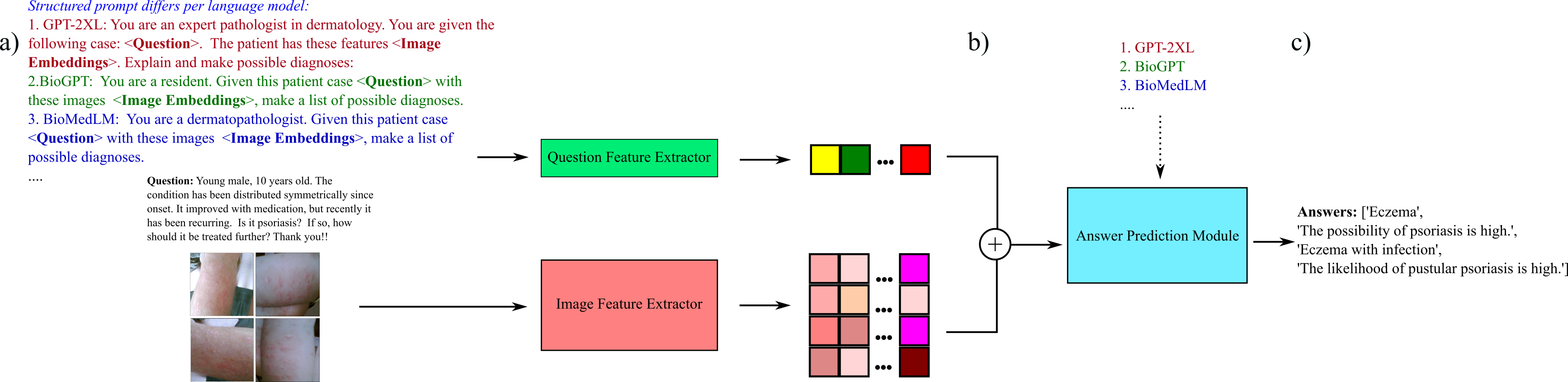
We take into account memory efficiency, and as such we implement model compression techniques for memory efficiency during fine-tuning, which includes 1) mixed-precision and 2) gradient accumulation to simulate mini-batch gradient descent. Answers are generated via greedy-search.
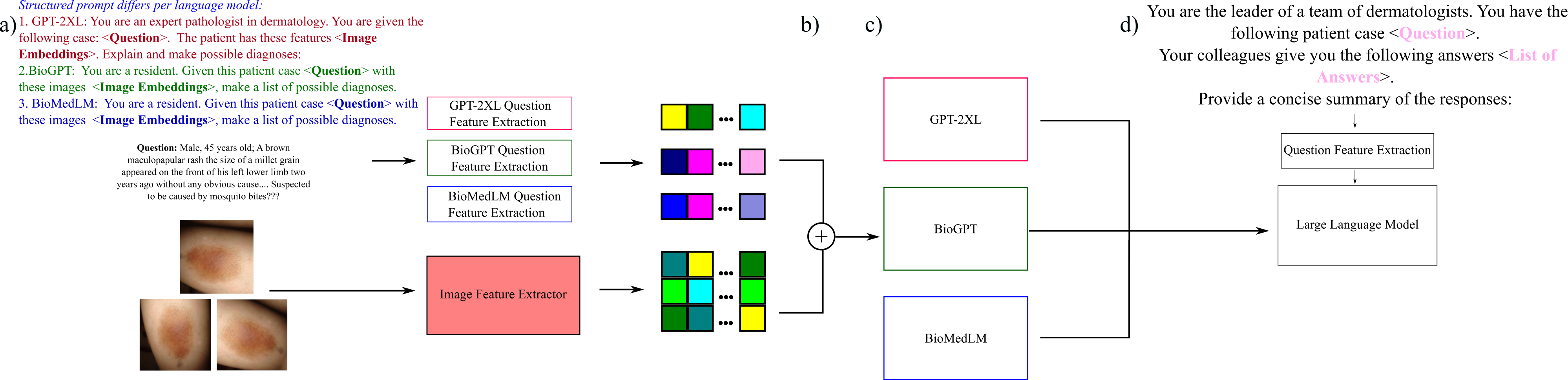
With memory efficiency concerns, the LLM is 1) quantized, 2) input tensors are loaded with 16-bit precision, 3) and a beam width of 1 (greedy search) is used for answer generation. The code is found at https://github.com/awxlong/manifold-medvqa/tree/main