El ritmo del progreso de Inteligencia Artificial: una experiencia personal
En resumen:
- Si te interesa, recomiendo empezar los más pronto posible a estudiar sobre aprendizaje profundo y tener una mente abierta que cualquier recurso en línea que accedas solamente está rascando la punta del iceberg sobre inteligencia artificial.
- No te sientas abrumado, el aprendizaje toma un tiempo y lo importante es que disfrutes lo que aprendas. Estate seguro de que la mayoría de conocimiento siguen principios comunes.
- Comparto un templete originalmente dibujado por mi profesor, Antonio Vergari, la cual te puede apoyar en tus estudios de modelos probabilísticos en tu vida colegial, universitaria, y, espero también, profesional.
Aprendizaje supervisado
Hace 3 años, empezando desde abril, 2020, audité un curso en línea que me introdujo a Aprendizaje Profundo (Deep Learning) organizado por el Prof. Andrew Ng y su equipo en Coursera. Fui introducido a varias arquitecturas de redes artificiales profundas, como las redes de convolución, redes recurrentes para resolver problemas con tablas de datos, con imágenes en la visión computacional o con una secuencia de textos en el ámbito de procesamiento de lenguaje natural respectivamente. Un principio omnipresente en la optimización de estas arquitecturas es el descenso estocástico de gradiente (DEG), ilustrado en la Figura 1. El DEG es usado para encontrar los parámetros óptimos que minimizan el error en las predicciones de las redes neuronales.
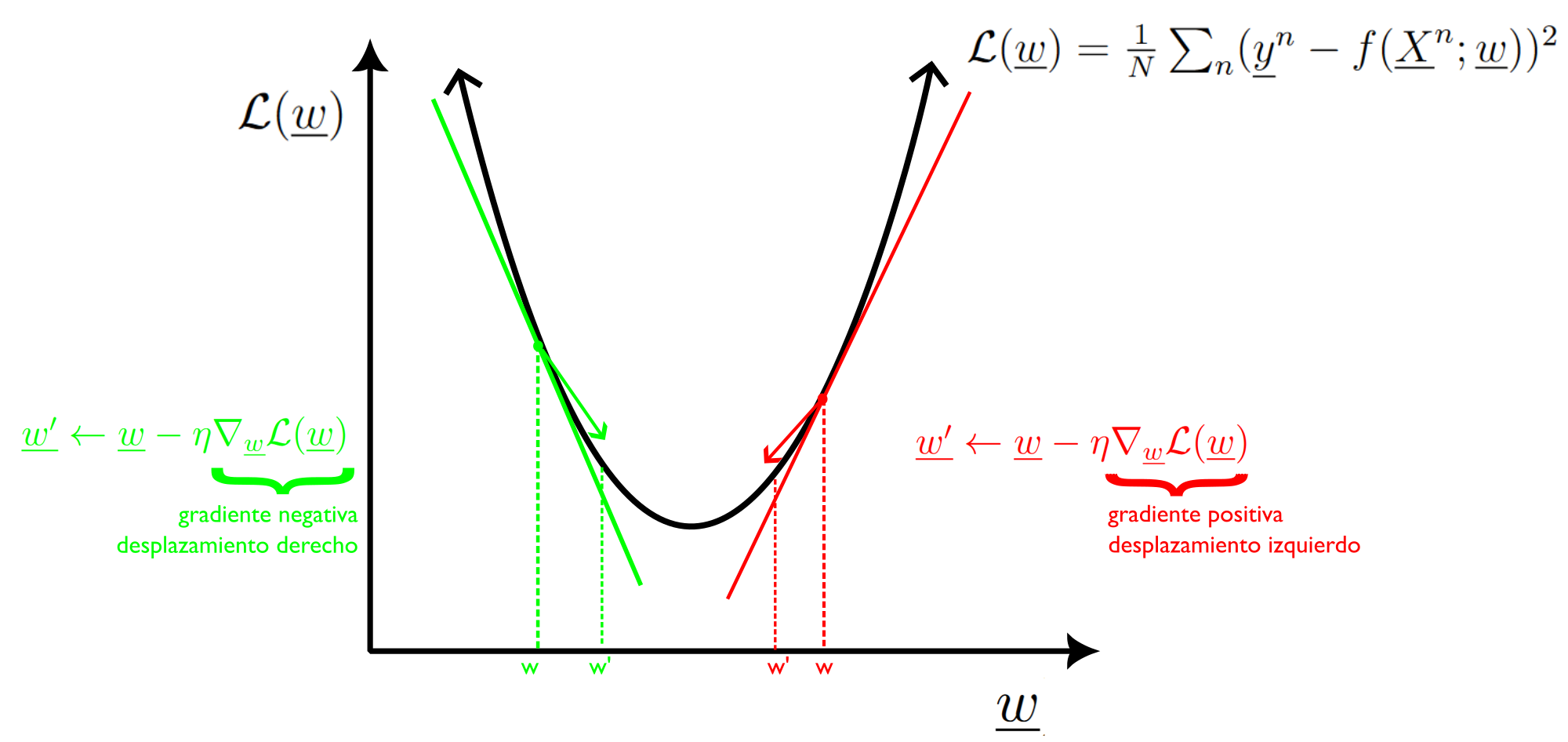
El denominador común de todas estas arquitecturas es que todas pertenecen al paradigma de aprendizaje “supervisado”. La atención a esta área es en gran parte catalizada por el éxito de una red profunda convolucional llamada AlexNet que había obtenido en 2012 la precisión de predicción más alta en una competencia de reconocimiento de objetos llamada ImageNet.

Modelos generativos
Debido a que el curso en línea de 5 partes revolvía sobre este tema, desde ese momento, pensé en la idea errónea de que aprendizaje “supervisado” era todo lo que aprendizaje profundo se trataba. A medida que los años pasan, el panorama de IA ha cambiado de manera muy rápida, y aunque aprendizaje supervisado sigue siendo dominante, este está enfrentando competencia de otras áreas. Hoy en día, si quisiera recomendar a un colega a cómo introducirse a aprendizaje profundo, definitivamente le recomendaría tomar cursos en línea como en Coursera, Udemy o YouTube, así como leer libros sobre aprendizaje mecánico como un prerrequisito. Sin embargo, quisiera agregar que se prepare con una mente abierta para aprender nuevos temas como aprendizaje no supervisado, afinamiento de modelos pre-entrenados, o modelos generativos, temas que en años recientes están readquiriendo atención.
Templete común de modelos de aprendizaje mecánico
Con esta afluencia torrencial de conocimiento, puede sentirse abrumador lo que hay que aprender. Algo que me ha ayudado bastante es poder encontrar los principios comunes detrás de la mayoría de estos modelos y métodos. O sea, un templete común de cual puedes instanciar o acomodar varias arquitecturas con el fin de entender cómo funcionan. Espero que el siguiente templete (Figura 2) te apoye en tus estudios de modelos de aprendizaje mecánico✌️, en tu jornada de aprender sobre modelos probabilísticos y redes neuronales:
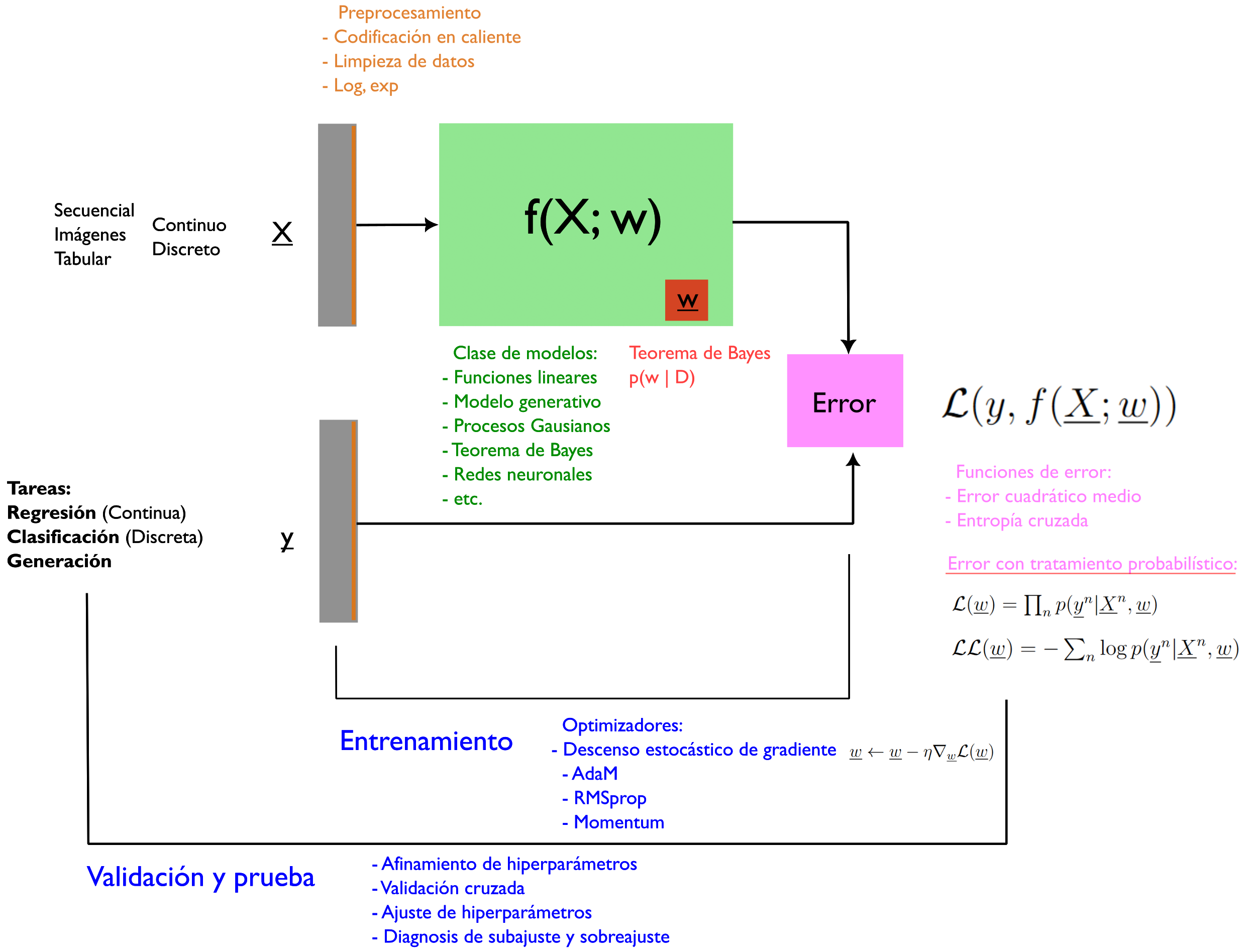
Por ejemplo, si estás aprendiendo sobre regresión lineal, entonces estás trabajando con X que consiste en dato tabular de columnas de variables continuas o discretas, mientras que y sería una columna de datos continuas. Estos datos tal vez pasen por una etapa de preprocesamiento en la cual limpies entradas nulas o vacías. El modelo regresión lineal es de la forma \(f(X;w)=w^T X^n\), un producto punto entre una fila de X y un vector de pesas w. Este modelo forma parte de una función de pérdida, en este caso el error cuadrático medio (ECM). Dentro del bucle interior de entrenamiento, el ECM es minimizado usando optimizadores que realizan el descenso estocástico de gradiente, con el fin de encontrar los parámetros óptimos del modelo f. En un bucle externo, el modelo f pasa por una etapa de validación y prueba para chequear varios problemas, por ejemplo si se ha subajustado o sobreajustado, y encontrar los hiperparámetros óptimos para minimizar la pérdida. Lo hermoso de este templete es que una diversidad amplias de otros modelos pueden ser instanciados de este, por ejemplo, una red neuronal sigue este esquema, con la diferencia de que en vez de un modelo f lineal, lo reemplazas con un modelo de capas neuronales. Los modelos generativos, los que están detrás de ChatGPT, también pueden ser entendidos en referencia a este templete: en vez de X ser una tabla de datos, esta es una secuencia de palabras, mientras que y sería X (por eso se llaman modelos generativos, porque aprenden a generar la base de datos suministrada), y la función de error usada recibe un tratamiento probabilístico.
¿Cómo será el panorama de inteligencia artificial en el futuro?
Si tuviese una opinión ahora, esta podría cambiar en 2 o 3 meses, y así de rápido es como siento el progreso de IA es. Sin embargo, aunque el ritmo de progreso es impresionantemente rápido, la mayoría de modelos probabilísticos siguen principios comunes ilustrados en la Figura 2. Espero que esto te sirva en tus estudios del aprendizaje profundo.
¡Suerte en tus estudios!
Favor compartir preguntas, comentarios y/o retroalimentación. Te agradecería bastante.
Enjoy Reading This Article?
Here are some more articles you might like to read next: