Brain-Heart Fractal, DALL-E and I
DALL-E and generative art
I have my share of skepticism of transformer-based models to generate art. My understanding of probability theory leads me to believe that a probabilistic model trained on a dataset can, at least interpolate, and, at most, extrapolate. Nonetheless, I don’t think creativity emerges from the averaging of past experiences or extrapolation of them. For example, consider a model like DALL-E which has learned from massive amounts of images what avocado and chair are. While it was impressive for it to generate an image when prompted with ‘avocado chair’ despite never being present, it is nowadays a ‘known unknown’. This is, such output can be readily explained by its capability to generate picture from the prompt, which we can think of as an extrapolation of both objects ‘avocado’ and ‘chair’ after seeing them for a large amount of times. Furthermore, both ‘avocado’ and ‘chair’ are real, natural objects, which empirically have been shown to be easier to learn than characters and numbers 1.
To me, art is also a reflection of the artist. However, since DALL-E has no prior life anecdotes, struggles or joyful moments for it to express through art, I personally find its generated art, no matter how grandiose they are advertised as they are through various mediums, to be shallow. I am greatly skeptical of whether it can generate a piece of work that is impactful and meaningful given a prompt such as “your understanding of peace and coexistence”.
Exploring prompts on complementarity of brain and heart
Nonetheless, if we disentangle DALL-E from the creation of art, and think of DALL-E as a tool for artists rather than fall for the frenzy discussion that AI is soon replacing artists and winning art competitions. In my view, that AI-generated art can win competitions reflects not a situation where AI is going to overtake humans in art (since AI didn’t even participate in this competition, it was a human who did, and prompted AI to generate a picture given specifications), but rather that we can elevate the standards of current competitions. I mean, wouldn’t it be incomprehensible if we pit humans against driverless automobiles in a race? We instead make racers on cars compete against other racers on cars. Therefore, I believe future competitions of art should allow artists to explore their humane creativity with the aid of DALL-E.
Given the above premise, I have indulged myself in exploring DALL-E powered image generators in the web, including Microsoft Bing Image Creator, Craiyon, Open AI’s Dall-E and DeepAI’s text-to-image generator. I didn’t focus with objects of the real world, such as space cats, Van Gogh-styled buildings or cyberpunk-ish characters, but rather focus on abstract concepts.
Given my interest in the consilience of knowledge and complementarity of seemingly opposing ideas, I wanted to instead try abstract ideas like “the complementarity of the brain and heart”. Before resorting to DALL-E, I gave a try myself in sketching the idea:
The following are some images generated by the above models:

I tried to be more specific, with prompts such as “brain and heart joined together harmoniously like the yin and yang”, “a depiction that the brain and heart work together harmoniously to make us human”, and “beautiful, intricate fractal shaped as the brain and heart innervated with one another, red, black and white”.
However, I do like some of the generations. I also share more images obtained from MS Bing’s Image Creator, which I mostly like. The prompts I used were “brain and heart interwoven made of fractals” and “brain and heart composed of fractals, high contrast red and black color”:
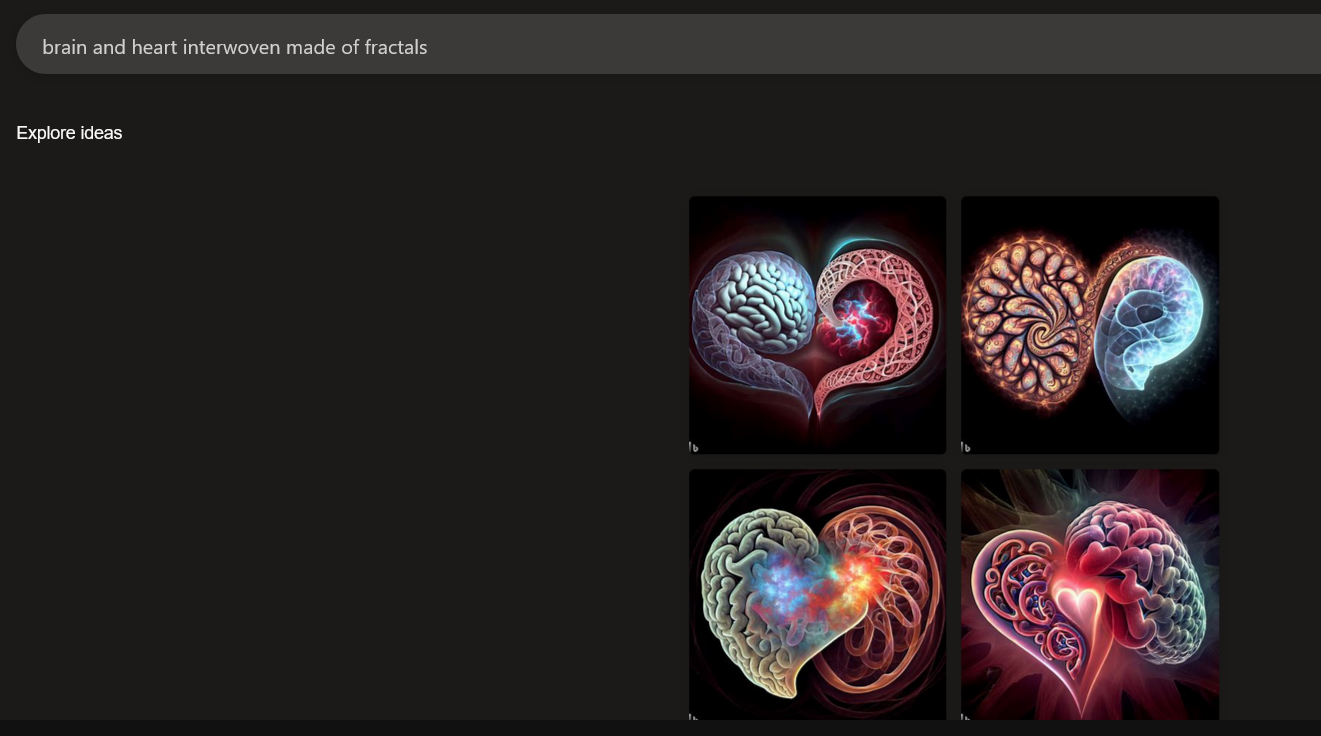
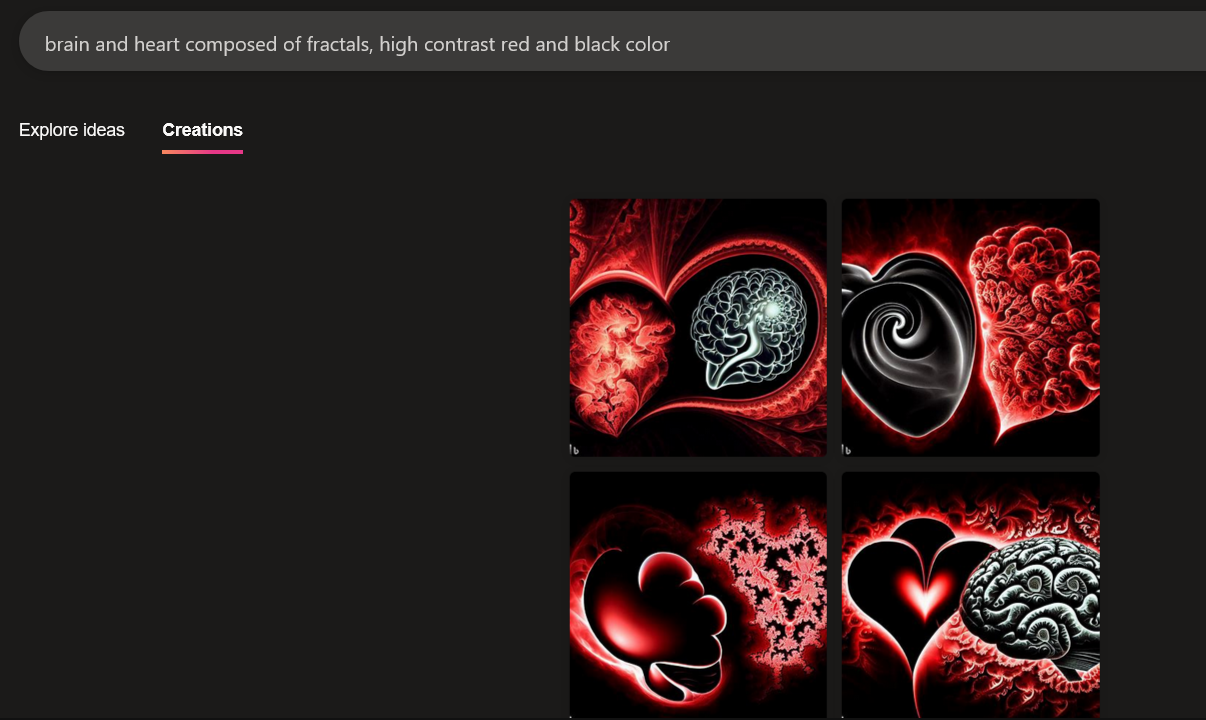
I’m actually using one of the images as my website icon.
There is a plethora of images I’m skipping since I generated too many with different prompts across platforms. And I may generate once in a while if I’m interested in checkpointing whether they have improved.
One of them which I also really liked is from DeepAI. I like the overall heart-shape, the colors used, and the presence of fractals:
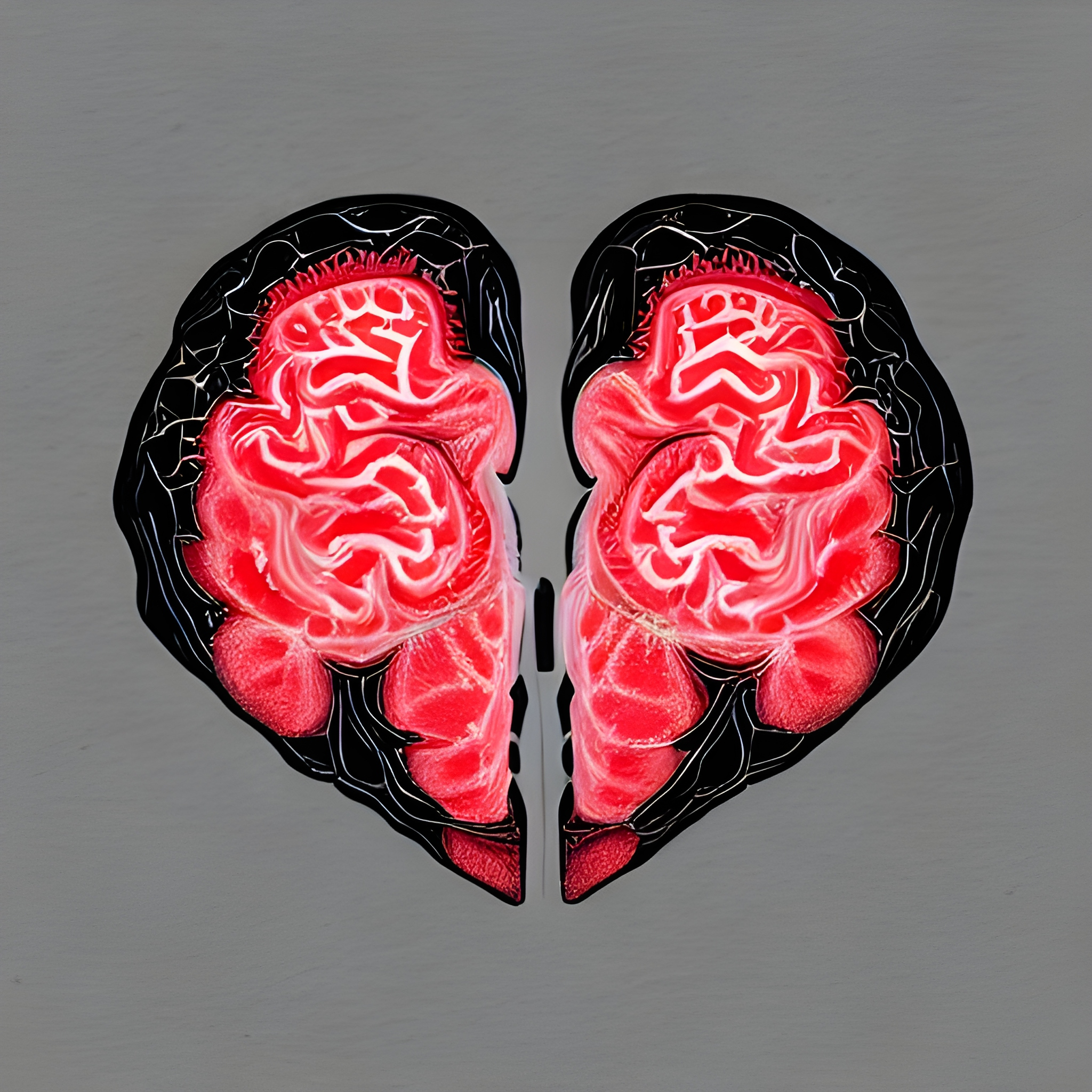
I really don’t think AI can replace artists. In general, I support the idea that “AI won’t replace [insert job profession]”, but rather “those who use AI will replace those who don’t”. I’m confident that anytime soon, AI models won’t be able to grasp high-level concepts since they lack their machine language which I believe is a tool to develop their own cognition for understanding the world. Even if they acquire machine language, they still need to evolve to grasp extremely complicated and intricate concepts like “complementarity”.
-
My own hypothesis for such behaviour is because the model lacks its own machine language for which it can understand the world. There are objective reasons for why an avocado and a chair are the way they are, either due to biology or human affordance. However, such objective reasons are not present in the presentation of concepts like numerosity or with letters. ↩
Enjoy Reading This Article?
Here are some more articles you might like to read next: